.
@@ -152,5 +152,5 @@ Para obtener más información, consulta @dax-script-introduction.
## Siguientes pasos
- @migrate-from-vs
-- @desarrollo-en-paralelo
-- @aumento-de-la-productividad-te3
+- @parallel-development
+- @boosting-productivity-te3
diff --git a/localizedContent/es/content/how-tos/undo-redo.md b/localizedContent/es/content/how-tos/undo-redo.md
index c74bf705..8526c2b3 100644
--- a/localizedContent/es/content/how-tos/undo-redo.md
+++ b/localizedContent/es/content/how-tos/undo-redo.md
@@ -13,4 +13,4 @@ applies_to:
Cualquier cambio que hagas en Tabular Editor se puede deshacer con CTRL+Z y, a continuación, rehacer con CTRL+Y. No hay límite en el número de operaciones que se pueden deshacer, pero la pila se restablece cuando abres un archivo Model.bim o cargas un modelo desde una base de datos.
-Si cometes un error, puedes usar la función Deshacer para restaurar el objeto eliminado, lo que también restaurará cualquier traducción, perspectiva o relación eliminada. Al eliminar objetos del modelo, todas las traducciones, perspectivas y relaciones que hagan referencia a los objetos eliminados también se eliminan automáticamente (mientras que Visual Studio normalmente muestra un mensaje de error indicando que el objeto no se puede eliminar). Ten en cuenta que, aunque Tabular Editor puede detectar [dependencias de fórmulas DAX](xref:formula-fix-up-dependencies), Tabular Editor no te avisará si eliminas una medida o una columna que se usa en la expresión DAX de otra medida o columna calculada.
\ No newline at end of file
+Al eliminar objetos del modelo, todas las traducciones, perspectivas y relaciones que hagan referencia a los objetos eliminados también se eliminan automáticamente (mientras que Visual Studio normalmente muestra un mensaje de error indicando que el objeto no se puede eliminar). Si cometes un error, puedes usar la función Deshacer para restaurar el objeto eliminado, lo que también restaurará cualquier traducción, perspectiva o relación eliminada. Ten en cuenta que, aunque Tabular Editor puede detectar [dependencias de fórmulas DAX](xref:formula-fix-up-dependencies), Tabular Editor no te avisará si eliminas una medida o una columna que se usa en la expresión DAX de otra medida o columna calculada.
\ No newline at end of file
diff --git a/localizedContent/es/content/references/preferences.md b/localizedContent/es/content/references/preferences.md
index 0c5ceeca..5094a425 100644
--- a/localizedContent/es/content/references/preferences.md
+++ b/localizedContent/es/content/references/preferences.md
@@ -176,7 +176,7 @@ Crea una copia de seguridad del modelo al guardar cambios localmente. Esto te of
##### _Ubicación para guardar la copia de seguridad_
-Especifica la carpeta donde se almacenan las copias de seguridad creadas al guardar. De forma predeterminada, no se crean copias de seguridad a menos que se especifique una ubicación.
+Especifica la carpeta donde se almacenan las copias de seguridad de los despliegues. De forma predeterminada, no se crean copias de seguridad a menos que se especifique una ubicación.
##### _Copia de seguridad al implementar_ (habilitado)
@@ -184,7 +184,7 @@ Crea una copia de seguridad del modelo de destino antes de implementar los cambi
##### _Ubicación de copia de seguridad_
-Especifica la carpeta donde se almacenan las copias de seguridad de los despliegues. De forma predeterminada, no se crean copias de seguridad a menos que se especifique una ubicación.
+De forma predeterminada, no se crean copias de seguridad a menos que se especifique una ubicación. Especifica la carpeta donde se almacenan las copias de seguridad creadas al guardar.
## Tabular Editor > Valores predeterminados
@@ -714,7 +714,7 @@ Define prefijos aceptables para nombres de variables (p. ej., `_`, `__`, `var_`,
Define prefijos aceptables para nombres de columnas temporales (p. ej., `@`, `_`, `x`, `x_`). Las acciones de código sugerirán añadir estos prefijos a los nombres de columnas temporales que no sigan la convención.
-## Editor SQL / Editor M / Editor de C\\#
+## Editor SQL / Editor M / Editor de C\#
![Marcador de posición: captura de pantalla de las páginas de preferencias de los editores SQL/M/C#]
diff --git a/localizedContent/es/content/security/security-privacy.md b/localizedContent/es/content/security/security-privacy.md
index 792f6d55..02462c0e 100644
--- a/localizedContent/es/content/security/security-privacy.md
+++ b/localizedContent/es/content/security/security-privacy.md
@@ -86,7 +86,7 @@ Tabular Editor puede realizar solicitudes a recursos en línea (URL web) solo en
- **Activación de licencia\*.** Cuando Tabular Editor 3 se inicia por primera vez y, posteriormente, a intervalos periódicos, la herramienta puede realizar una solicitud a nuestro servicio de licencias. Esta solicitud contiene información cifrada sobre la clave de licencia introducida por el usuario, la dirección de correo electrónico del usuario (si se proporciona), el nombre del equipo local y un hash codificado unidireccional que identifica la instalación actual. No se transmite ningún otro dato en esta solicitud. El propósito de esta solicitud es activar y validar la clave de licencia utilizada por la instalación, aplicar las limitaciones de la versión de prueba y permitir que el usuario gestione sus instalaciones de Tabular Editor 3 a través de nuestro servicio de licencias.
- **Comprobaciones de actualización\*.** Cada vez que se inicia Tabular Editor 3, puede realizar una solicitud a nuestro servicio de aplicaciones para determinar si hay disponible una versión más reciente de Tabular Editor 3. Esta solicitud no contiene ningún dato.
-- **Telemetría de uso\*.** De forma predeterminada, Tabular Editor 3 recopila y transmite datos de uso anónimos a medida que los usuarios interactúan con la herramienta. Estos datos incluyen información sobre los objetos de la interfaz de usuario con los que interactúa un usuario y el momento de cada interacción. También contiene información de alto nivel sobre el Data model tabular que se está editando con la herramienta. Esta información solo se refiere a propiedades de alto nivel como el nivel de compatibilidad y el modo, el número de tablas, el tipo de servidor (Analysis Services vs. Power BI vs. Power BI Desktop), etc. **No se recopilan datos personales identificables de esta manera**, ni recopilamos información sobre los nombres de los objetos o las expresiones DAX en el propio Tabular Object Model. Un usuario puede optar por no enviarnos datos de telemetría en cualquier momento.
+- **Telemetría de uso\*.** De forma predeterminada, Tabular Editor 3 recopila y transmite datos de uso anónimos a medida que los usuarios interactúan con la herramienta. Estos datos incluyen información sobre los objetos de la interfaz de usuario con los que interactúa un usuario y el momento de cada interacción. También contiene información de alto nivel sobre el Data model tabular que se está editando con la herramienta. Un usuario puede optar por no enviarnos datos de telemetría en cualquier momento. Esta información solo se refiere a propiedades de alto nivel como el nivel de compatibilidad y el modo, el número de tablas, el tipo de servidor (Analysis Services vs. Power BI vs. Power BI Desktop), etc. **No se recopilan datos personales identificables de esta manera**, ni recopilamos información sobre los nombres de los objetos o las expresiones DAX en el propio Tabular Object Model.
- **Reports de error\*.** Cuando se produce un error inesperado, transmitimos la traza de la pila y los mensajes de error (anonimizados), junto con una descripción opcional proporcionada por el usuario. Si un usuario decide no enviar datos de telemetría, tampoco se enviarán los Reports de error.
- **Uso del formateador de DAX.** (Solo Tabular Editor 2.x) Se puede dar formato a una expresión DAX haciendo clic en un botón en Tabular Editor. En este caso, la expresión DAX (y nada más) se envía al servicio web www.daxformatter.com. La primera vez que un usuario hace clic en este botón, se muestra un mensaje de advertencia explícito para que confirme su intención. Tabular Editor 3 no realiza solicitudes web al dar formato al código DAX.
- **Optimizador de DAX**. Si un usuario tiene una [cuenta de Tabular Tools](https://tabulartools.com) con una suscripción a [Optimizador de DAX](https://daxoptimizer.com), podrá explorar su Workspace del Optimizador de DAX, ver incidencias y sugerencias, y cargar nuevos archivos VPAX directamente desde Tabular Editor 3. Los archivos VPAX contienen metadatos y estadísticas del modelo, pero no _datos_ reales del modelo. La función de integración del Optimizador de DAX en Tabular Editor 3 realiza varias solicitudes a uno o varios de los endpoints indicados a continuación (en función del tipo de autenticación y de la región especificados al crear la cuenta de Tabular Tools).
diff --git a/localizedContent/es/content/tutorials/incremental-refresh/incremental-refresh-about.md b/localizedContent/es/content/tutorials/incremental-refresh/incremental-refresh-about.md
index abc0e42a..02787629 100644
--- a/localizedContent/es/content/tutorials/incremental-refresh/incremental-refresh-about.md
+++ b/localizedContent/es/content/tutorials/incremental-refresh/incremental-refresh-about.md
@@ -297,31 +297,31 @@ _A continuación se muestra un resumen de las propiedades de TOM de un Data mode
| EnableRefreshPolicy |
Actualizar esta tabla de forma incremental |
- Indica si hay una política de actualización habilitada para la tabla.
En Tabular Editor, otras propiedades de la política de actualización solo serán visibles si este valor se establece en True. |
+ Indica si la tabla tiene habilitada una política de actualización.
En Tabular Editor, el resto de las propiedades de la política de actualización solo se mostrarán si este valor se establece en True. |
True o False. |
| IncrementalGranularity |
Período de actualización incremental |
- La granularidad de la ventana incremental.
Ejemplo:
"Actualice los datos de los últimos 30 días antes de la fecha de actualización." |
- Day, Month, Quarter o Year. Debe ser menor o igual que el valor de IncrementalGranularity. |
+ La granularidad de la ventana incremental.
Ejemplo:
"Actualizar los datos de los últimos 30 días anteriores a la fecha de actualización." |
+ Day, Month, Quarter o Year. Debe ser menor o igual que el IncrementalGranularity. |
| IncrementalPeriods |
Número de períodos de actualización incremental |
- El número de períodos de la ventana incremental.
Ejemplo:
"Actualice los datos de los últimos 30 días antes de la fecha de actualización." |
- Un número entero que indica la cantidad de períodos de IncrementalGranularity. Debe definir un período total inferior a RollingWindowPeriods |
+ El número de períodos de la ventana incremental.
Ejemplo:
"Actualizar los datos de los últimos 30 días antes de la fecha de actualización." |
+ Un número entero que indique el número de períodos de IncrementalGranularity. Debe definir un período total inferior a RollingWindowPeriods |
| IncrementalPeriodsOffset |
- Actualizar solo los días completos |
+ Actualizar solo días completos |
El desplazamiento que se aplicará a IncrementalPeriods.
Ejemplo para:
IncrementalPeriodsOffset=-1;
IncrementalPeriods = 30;
IncrementalGranularity = Day:
"Actualizar solo los datos de los últimos 30 días, desde el día anterior a la fecha de actualización. |
- Un número entero que indica la cantidad de períodos de IncrementalGranularity para desplazar la ventana incremental. |
+ Un número entero con el número de períodos de IncrementalGranularity para desplazar la ventana incremental. |
| Mode |
- Obtener los datos más recientes en tiempo real con DirectQuery |
- Especifica si la actualización incremental está configurada solo con particiones de importación o también con una partición de DirectQuery, para crear una "tabla híbrida". |
+ Obtenga los datos más recientes en tiempo real con DirectQuery |
+ Especifica si la actualización incremental se configura únicamente con particiones de importación o también con una partición de DirectQuery, para dar como resultado una "tabla híbrida". |
Import o Hybrid. |
@@ -333,7 +333,7 @@ _A continuación se muestra un resumen de las propiedades de TOM de un Data mode
PollingExpression
(Opcional) |
Detectar cambios en los datos |
- La expresión M utilizada para detectar cambios en una columna específica, como LastUpdateDate.
En Tabular Editor, la Polling Expression se puede ver y modificar desde la ventana del Editor de expresiones seleccionándola en el menú desplegable de la esquina superior izquierda. | Una expresión M válida que devuelve un valor escalar de la fecha más reciente de una columna. Se actualizarán todos los registros de las particiones activas de la ventana incremental que contengan ese valor en la columna.
Los registros de las particiones archivadas no se actualizan. |
+ La expresión M que se usa para detectar cambios en una columna específica, como LastUpdateDate
En Tabular Editor, la PollingExpression se puede ver y modificar desde la ventana del Editor de expresiones seleccionándola en el menú desplegable de la esquina superior izquierda. | Una expresión M válida que devuelve un valor escalar de la fecha más reciente de una columna. Se actualizarán todos los registros de las particiones activas de la ventana incremental que contengan ese valor en la columna.
Los registros de las particiones archivadas no se actualizan. |
| RollingWindowGranularity |
diff --git a/localizedContent/zh/content/_ui-strings.json b/localizedContent/zh/content/_ui-strings.json
index 5525fb60..cfffdf19 100644
--- a/localizedContent/zh/content/_ui-strings.json
+++ b/localizedContent/zh/content/_ui-strings.json
@@ -35,5 +35,14 @@
"themeAuto": "自动",
"changeTheme": "切换主题",
"copy": "复制",
- "downloadPdf": "下载 PDF"
+ "downloadPdf": "下载 PDF",
+ "search": "搜索文档",
+ "note": "注意",
+ "warning": "警告",
+ "tip": "提示",
+ "important": "重要",
+ "caution": "注意事项",
+ "tableOfContents": "目录",
+ "selectLanguage": "选择语言",
+ "copyCode": "复制代码"
}
diff --git a/localizedContent/zh/content/api/index.md b/localizedContent/zh/content/api/index.md
index 03eab007..b2204853 100644
--- a/localizedContent/zh/content/api/index.md
+++ b/localizedContent/zh/content/api/index.md
@@ -7,15 +7,15 @@ updated: 2026-01-27
# Tabular Editor API
-这是 Tabular Editor 的 C# 脚本编写功能的 API 文档。
+这是 Tabular Editor 的 C# Script 功能的 API 文档。
-具体而言,可用于脚本编写的对象来自 **TOMWrapper.dll**、**TabularEditor3.Shared.dll** 和 **SemanticBridge.dll** 库。
+具体来说,可用于编写脚本的对象来自 **TOMWrapper.dll**、**TabularEditor3.Shared.dll** 和 **SemanticBridge.dll** 库。
-## 入门
+## 开始使用
-在 Tabular Editor 中编写脚本时,最常用的两个对象是 [`Selected`](xref:TabularEditor.Shared.Interaction.Selection),它允许你访问当前在 TOM Explorer 中选中的对象,以及 [`Model`](xref:TabularEditor.TOMWrapper.Model),它允许你访问当前加载的数据模型中的任何对象。 这两个对象都作为全局 [`ScriptHost`](xref:TabularEditor.Shared.Scripting.ScriptHost) 对象的成员属性提供。
+在 Tabular Editor 中编写脚本时,最常用的两个对象是 [`Selected`](xref:TabularEditor.Shared.Interaction.Selection) 和 [`Model`](xref:TabularEditor.TOMWrapper.Model)。前者可让你访问当前在 TOM Explorer 中选中的对象,后者可让你访问当前已加载的 Data model 中的任何对象。 这两个对象都可作为全局 [`ScriptHost`](xref:TabularEditor.Shared.Scripting.ScriptHost) 对象的成员属性使用。
-此外,`ScriptHost` 对象还包含一些静态方法,这些方法会以全局方法的形式暴露给脚本(也就是说,你可以直接调用它们,无需加上 `ScriptHost` 前缀)。 这些方法也称为 @script-helper-methods(脚本帮助方法)。
+此外,`ScriptHost` 对象还包含一些静态方法,这些方法会作为全局方法向脚本公开(也就是说,无需加上 `ScriptHost` 前缀即可调用)。 这些方法也称为 @script-helper-methods。
## 示例
@@ -23,8 +23,8 @@ updated: 2026-01-27
// 显示一个对话框,提示用户选择一个度量值:
var myMeasure = SelectMeasure();
-// 在模型的第一张表上创建一个新度量值,其名称和表达式
-// 与前面选中的度量值相同:
+// 在模型的第一张表上创建一个新的度量值,其名称和表达式
+// 与先前选中的度量值相同:
Model.Tables.First().AddMeasure(myMeasure.Name + " copy", myMeasure.Expression);
```
diff --git a/localizedContent/zh/content/features/Best-Practice-Analyzer.md b/localizedContent/zh/content/features/Best-Practice-Analyzer.md
index 08f08a98..79cf2b36 100644
--- a/localizedContent/zh/content/features/Best-Practice-Analyzer.md
+++ b/localizedContent/zh/content/features/Best-Practice-Analyzer.md
@@ -1,85 +1,85 @@
---
uid: best-practice-analyzer
-title: 最佳实践分析器
+title: Best Practice Analyzer
applies_to:
products:
- product: Tabular Editor 2
full: true
- product: Tabular Editor 3
editions:
- - edition: Desktop
+ - edition: 桌面版
full: true
- - edition: Business
+ - edition: 商业版
full: true
- - edition: Enterprise
+ - edition: 企业版
full: true
---
-# 最佳实践分析器
+# Best Practice Analyzer
-自 [Tabular Editor 2.8.1](https://github.com/TabularEditor/TabularEditor/releases/tag/2.8.1) 起,最佳实践分析器已进行了重大改版。
+自 [Tabular Editor 2.8.1](https://github.com/TabularEditor/TabularEditor/releases/tag/2.8.1) 起,Best Practice Analyzer 迎来了一次重大改版。
-你首先会注意到,Tabular Editor 现在会在主 UI 中直接显示最佳实践问题的数量:
+你首先会注意到,Tabular Editor 现在会在主界面中直接报告最佳实践问题的数量:
-
+
-每当对模型进行更改时,最佳实践分析器都会在后台扫描你的模型以查找问题。 你可以在“文件 > 偏好设置”中禁用此功能。
+每当模型发生更改时,Best Practice Analyzer 都会在后台扫描你的模型以查找问题。 你可以在“文件 > 偏好设置”中禁用此功能。
-点击该链接(或按 F10),会打开全新升级的最佳实践分析器 UI:
+单击该链接(或按 F10)会打开全新改进后的 Best Practice Analyzer 界面:
-
+
-如果你在旧版本中用过最佳实践分析器,你首先会注意到该 UI 已完全重新设计,占用的屏幕空间更小。 这样你就可以将该窗口停靠在桌面一侧,同时将主窗口放在另一侧,从而同时操作两者。
+如果你在早期版本中用过 Best Practice Analyzer,首先会注意到它的界面已被彻底重新设计,占用的屏幕空间更少。 这样一来,你可以将该窗口停靠在屏幕的一侧,同时将主窗口放在另一侧,从而同时使用两者。
-最佳实践分析器窗口会持续列出模型中所有 **生效规则**,以及违反各规则的对象。 在列表中的任意位置右键单击,或使用窗口顶部的工具栏按钮,即可执行以下操作:
+Best Practice Analyzer 窗口会持续列出适用于你的模型的所有**有效规则**,以及违反各项规则的对象。 在列表中的任意位置右键单击,或使用窗口顶部工具栏上的按钮,即可执行以下操作:
-- **管理规则...**:打开“管理规则”界面,我们将在下文介绍。 你也可以在主界面通过“工具 > 管理 BPA 规则...”菜单打开此界面。
-- **转到对象...**:选择此选项,或在列表中双击某个对象,会在主界面中定位到同一对象。
-- **忽略项(单个/多个)**:在列表中选择一个或多个对象并选择此选项,会为所选对象添加注释,表明 Best Practice Analyzer 今后应忽略这些对象。 如果你误将某个对象设为忽略,请点击屏幕顶部的“显示已忽略”按钮。 这样你就可以取消忽略之前被忽略的对象。
-- **忽略规则**:如果你在列表中选择了一条或多条规则,此选项会在模型级别添加一条注释,用于指示所选规则应始终被忽略。 同样,通过切换“显示已忽略”按钮,你也可以取消忽略这些规则。
-- **生成修复脚本**:对于可轻松修复的规则(即只需在对象上设置一个属性就能解决问题),将启用此选项。 点击后,会将一个 C# Script 复制到剪贴板。 然后,你可以将该脚本粘贴到 Tabular Editor 的 [高级脚本](../how-tos/Advanced-Scripting.md) 区域中,在执行以应用修复之前先进行检查。
-- **应用修复**:如上所述,此选项也适用于可轻松修复的规则。 它不会将脚本复制到剪贴板,而是立即执行。
+- **管理规则...**:这会打开“管理规则”界面,下面会详细介绍。 也可以通过主界面的“工具 > 管理 BPA 规则...”菜单打开此界面。
+- **转到对象...**:选择此选项,或在列表中双击某个对象,都会在主界面中定位到该对象。
+- **忽略项/多项**:在列表中选择一个或多个对象并使用此选项后,系统会为所选对象添加一条注释,指示 Best Practice Analyzer 后续忽略这些对象。 如果你误忽略了某个对象,可以切换窗口顶部的“显示已忽略”按钮。 这样你就可以取消忽略之前已被忽略的对象。
+- **忽略规则**:如果你已在列表中选择了一条或多条规则,此选项会在模型级别添加一条注释,用于指示应始终忽略所选规则。 同样,通过切换“显示已忽略项”按钮,你也可以取消对规则的忽略。
+- **生成修复脚本**:对于可轻松修复的规则(即只需在对象上设置单个属性即可解决问题),将启用此选项。 点击后,会将一段 C# Script 复制到你的剪贴板。 随后,你可以将该脚本粘贴到 Tabular Editor 的 [Advanced Scripting](../how-tos/Advanced-Scripting.md) 区域,在执行以应用修复之前先进行检查。
+- **应用修复**:如上所述,此选项同样适用于可轻松修复的规则。 脚本不会被复制到剪贴板,而是会立即执行。
## 管理最佳实践规则
-如果你需要添加、删除或修改应用于模型的规则,这里也提供了一套全新的 UI。 你可以通过点击 Best Practice Analyzer 窗口左上角的按钮将其调出,或在主窗口中使用 "Tools > Manage BPA Rules..." 菜单项。
+如果你需要添加、删除或修改应用于模型的规则,这里也提供了一个全新的 UI 来完成这些操作。 你可以通过点击 Best Practice Analyzer 窗口左上角的按钮打开它,也可以在主窗口中使用“Tools > Manage BPA Rules...”菜单项。
-
+
-该 UI 包含两个列表:上方列表表示当前已加载的规则的 **集合**。 在此列表中选择一个规则集后,下方列表会显示该规则集中定义的所有规则。 默认会显示三个规则集:
+该界面包含两个列表:上方列表显示当前已加载的**规则集**。 在此列表中选择某个规则集后,下方列表会显示该规则集中定义的所有规则。 默认会显示三个规则集:
-- **当前模型中的规则**:顾名思义,这是在当前模型中定义的规则集。 规则定义以注释的形式存储在 Model 对象上。
-- **本地用户规则**:这些规则存储在您的 `%AppData%\..\Local\TabularEditor3\BPARules.json` 文件(Tabular Editor 3)或 `%AppData%\..\Local\TabularEditor\BPARules.json` 文件(Tabular Editor 2)中。 这些规则将应用于当前登录的 Windows 用户在 Tabular Editor 中加载的所有模型。
-- **本机上的规则**:这些规则存储在 `%ProgramData%\TabularEditor\BPARules.json` 文件中。 这些规则将应用于当前机器上在 Tabular Editor 中加载的所有模型。
+- **当前模型中的规则**:顾名思义,这是在当前模型内定义的规则集。 这些规则定义作为注释存储在 Model 对象上。
+- **本地用户规则**:这些规则存储在 `%AppData%\\..\\Local\\TabularEditor3\\BPARules.json` 文件(Tabular Editor 3)或 `%AppData%\\..\\Local\\TabularEditor\\BPARules.json` 文件(Tabular Editor 2)中。 这些规则将应用于当前登录的 Windows 用户在 Tabular Editor 中加载的所有模型。
+- **本地计算机上的规则**:这些规则存储在 `%ProgramData%\TabularEditor\BPARules.json` 中。 这些规则将应用于当前计算机上在 Tabular Editor 中加载的所有模型。
-如果同一条规则(按 ID)同时存在于多个规则集中,则优先级从上到下:也就是说,模型中定义的规则会优先于本机上定义的同 ID 规则。 这样你就可以覆盖现有规则,例如以便考虑模型特定的约定。
+如果多个规则集中都包含同一条规则(按 ID),则优先级从上到下。也就是说,模型内定义的规则优先于本地计算机上定义的同 ID 规则。 这样你就可以覆盖现有规则,例如将模型特定的约定考虑在内。
-在列表顶部,你会看到一个名为 **(Effective rules)** 的特殊集合。 选择此规则集后,将显示实际应用于当前加载模型的规则列表,并会遵循上述相同 ID 规则的优先级。 下方列表会标明每条规则属于哪个规则集。 此外,如果在优先级更高的规则集中已存在 ID 相近的规则,你会看到该规则的名称会被划线显示:
+在列表顶部,你会看到一个名为 **(Effective rules)** 的特殊集合。 选择此集合后,你将看到实际应用于当前已加载模型的规则列表,并会按前文所述遵循相同 ID 规则的优先级。 下方列表会指明每条规则所属的规则集。 此外,如果在优先级更高的集合中存在 ID 相同的规则,你会注意到该规则的名称会显示为删除线:

-### 添加额外规则集
+### 添加更多规则集
-Tabular Editor 2.8.1 的一项新功能是:可以在模型中包含来自其他来源的规则。 例如,如果你有一个存放在网络共享上的规则文件,现在可以将该文件作为规则集包含到当前模型中。 如果你对该文件所在位置有写入权限,还可以在该文件中添加/修改/删除规则。 以这种方式添加的规则集,其优先级高于模型内定义的规则。 如果你添加了多个此类规则集,可以通过上下移动它们来控制彼此之间的优先级。
+Tabular Editor 2.8.1 的一项新功能是,可以在模型中包含来自其他来源的规则。 例如,如果你的某个规则文件位于网络共享上,现在可以将该文件作为规则集包含到当前模型中。 如果你对该文件所在位置具有写入权限,还可以添加/修改/删除该文件中的规则。 以这种方式添加的规则集,其优先级高于模型内定义的规则。 如果你添加了多个此类规则集,可以通过上移和下移来控制它们之间的优先级。
-点击“添加...”按钮,将新的规则集添加到模型中。 这会提供以下选项:
+点击“添加...”按钮,将新规则集添加到模型中。 这会提供以下选项:

-- **创建新规则文件**:将在指定位置创建一个新的空的 .json 文件,之后你可以向其中添加规则。 选择文件时请注意:可以使用相对文件路径。 当你希望将规则文件与当前模型存放在同一个代码仓库中时,这会很有用。 不过请注意:相对路径的规则文件引用仅在模型从磁盘加载时才有效(因为从 Analysis Services 实例加载模型时没有工作目录)。
-- **包含本地规则文件**:如果你已经有一个包含规则的 .json 文件,并希望将其包含到模型中,请使用此选项。 同样,你也可以选择使用相对文件路径;如果该文件与模型元数据位置相近,这会更方便。 如果文件位于网络共享上(或更一般地说,位于与当前加载的模型元数据不同的驱动器上),则只能使用绝对路径来包含它。
-- **从 URL 包含规则文件**:使用此选项可指定一个 HTTP/HTTPS URL,该 URL 应返回有效的规则定义(JSON)。 如果你希望从在线来源包含规则,这会很有用。例如,来自 [BestPracticeRules GitHub 站点](https://github.com/microsoft/Analysis-Services/tree/master/BestPracticeRules) 的[标准 BPA 规则](https://raw.githubusercontent.com/microsoft/Analysis-Services/master/BestPracticeRules/BPARules.json)。 注意:从在线来源添加的规则集将是只读的。
+- **创建新规则文件**:这会在指定位置创建一个新的空 .json 文件,之后你可以向其中添加规则。 选择文件时,注意有一个使用相对文件路径的选项。 如果你希望将规则文件存储在与当前模型相同的 repository 中,这会很有用。 但要注意,相对规则文件引用仅在模型从磁盘加载时才有效(因为从 Analysis Services 实例加载模型时不存在工作目录)。
+- **包含本地规则文件**:如果你已经有一个包含规则的 .json 文件,并想把它包含到模型中,就用这个选项。 同样,你也可以使用相对文件路径;如果该文件位于靠近模型元数据的位置,这会更方便。 如果该文件位于网络共享上(或者更一般地说,位于与当前已加载模型元数据所在位置不同的驱动器上),则只能使用绝对路径来包含它。
+- **从 URL 包含规则文件**:此选项允许你指定一个 HTTP/HTTPS URL,该 URL 应返回有效的规则定义(JSON)。 如果你想包含来自在线来源的规则,这会很有用,例如来自 [BestPracticeRules GitHub 站点](https://github.com/microsoft/Analysis-Services/tree/master/BestPracticeRules) 的 [标准 BPA 规则](https://raw.githubusercontent.com/microsoft/Analysis-Services/master/BestPracticeRules/BPARules.json)。 注意,从在线来源添加的规则集将是只读的。
### 修改规则集中的规则
-在你对规则集存储位置拥有写入权限的前提下,屏幕下半部分可让你在当前选中的规则集中添加、编辑、克隆和删除规则。 此外,“移动到...”按钮允许你将所选规则移动或复制到另一个规则集,便于管理多个规则集。
+屏幕下半部分允许你在当前选中的规则集中添加、编辑、克隆和删除规则,前提是你对该规则集的存储位置具有写入权限。 此外,“移动到...”按钮允许你将所选规则移动或复制到另一个规则集,从而更轻松地管理多个规则集。
### 规则说明占位符
-与之前版本相比,有一个小改进:现在你可以在“最佳实践规则”的描述中使用以下占位符值。 这将提供更多可自定义的描述,这些描述会在“最佳实践”界面中以工具提示的形式显示:
+相比之前版本有一个小改进:现在你可以在最佳实践规则的说明中使用以下占位符值。 这将提供更多可自定义的说明,并在“最佳实践”界面中以工具提示的形式显示:
-- `%object%` 返回对当前对象的完全限定 DAX 引用(如适用)
+- `%object%` 返回当前对象的完全限定 DAX 引用(如适用)
- `%objectname%` 仅返回当前对象的名称
- `%objecttype%` 返回当前对象的类型
-
+
diff --git a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-add-databricks-metadata-descriptions.md b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-add-databricks-metadata-descriptions.md
index a1f8c5f5..a06d668c 100644
--- a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-add-databricks-metadata-descriptions.md
+++ b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-add-databricks-metadata-descriptions.md
@@ -15,12 +15,12 @@ applies_to:
## 脚本用途
-此脚本是 Tabular Editor x Databricks 系列的一部分。 在 Unity Catalog 中,可以为表和列添加描述性注释。 此脚本可以复用这些信息,自动填充语义模型中的表和列描述。
+这个脚本是 Tabular Editor x Databricks 系列的一部分。 在 Unity Catalog 中,可以为表和列添加描述性注释。 此脚本可复用这些信息,自动补全语义模型中的表和列说明。
> [!NOTE]
-> 此脚本需要安装 Simba Spark ODBC Driver(可从 https://www.databricks.com/spark/odbc-drivers-download 下载)
-> 每次运行脚本都会提示用户输入 Databricks 个人访问令牌。 这是连接 Databricks 并完成身份验证所必需的。
-> 脚本会使用 Unity Catalog 中的 information_schema 表来检索关系信息,因此你可能需要与 Databricks 管理员确认,确保你有权限查询这些表。
+> 这个脚本需要先安装 Simba Spark ODBC Driver(可从 https://www.databricks.com/spark/odbc-drivers-download 下载)
+> 每次运行脚本时,都会提示你输入 Databricks 个人访问令牌。 这是用于向 Databricks 进行身份验证所必需的。
+> 这个脚本使用 Unity Catalog 中的 information_schema 表来检索关系信息,因此你可能需要和你的 Databricks 管理员再确认一下,确保你有权限查询这些表。
## 脚本
@@ -28,20 +28,20 @@ applies_to:
```csharp
/*
- * Title: Add Databricks Metadata descriptions
- * Author: Johnny Winter, greyskullanalytics.com
+ * 标题:添加 Databricks 元数据说明
+ * 作者:Johnny Winter, greyskullanalytics.com
*
- * This script, when executed, will loop through the currently selected tables and send a query to Databricks to see if each table has metadata descriptions defined in Unity Catalog.
- * Where a description exists, this will be added to the semantic model description.
- * Step 1: Select one or more tables in the model
- * Step 2: Run this script
- * Step 3: Enter your Databricks Personal Access Token when prompted
- * Step 4: The script will connect to Databricks and update the table and column descriptions where they exist.
- * For each table processed, a message box will display the number of descriptions updated.
- * Click OK to continue to the next table.
- * Notes:
- * - This script requires the Simba Spark ODBC Driver to be installed (download from https://www.databricks.com/spark/odbc-drivers-download)
- * - Each run of the script will prompt the user for a Databricks Personal Access Token
+ * 运行这个脚本时,它会遍历当前选中的表,并向 Databricks 发送查询,检查每个表是否在 Unity Catalog 中定义了元数据说明。
+ * 如果有说明,就会把它添加到语义模型的说明中。
+ * 步骤 1:在模型中选择一个或多个表
+ * 步骤 2:运行这个脚本
+ * 步骤 3:在出现提示时输入你的 Databricks 个人访问令牌
+ * 步骤 4:脚本会连接到 Databricks,并在表和列存在说明时更新对应说明。
+ * 对于处理的每个表,都会显示一个消息框,指出已更新的说明数量。
+ * 点击“确定”继续处理下一个表。
+ * 备注:
+ * - 这个脚本需要先安装 Simba Spark ODBC Driver(可从 https://www.databricks.com/spark/odbc-drivers-download 下载)
+ * - 每次运行脚本时,都会提示你输入 Databricks 个人访问令牌
*/
#r "Microsoft.VisualBasic"
using System;
@@ -52,7 +52,7 @@ using System.Windows.Forms;
using Microsoft.VisualBasic;
using sysData = System.Data;
-//code to create a masked input box for Databricks PAT token
+//用于创建 Databricks PAT 令牌掩码输入框的代码
public partial class PasswordInputForm : Form
{
public string Password { get; private set; }
@@ -76,7 +76,7 @@ public partial class PasswordInputForm : Form
this.MaximizeBox = false;
this.MinimizeBox = false;
- // Prompt label
+ //提示标签
promptLabel = new Label();
promptLabel.Text = prompt;
promptLabel.Location = new System.Drawing.Point(12, 15);
@@ -84,11 +84,11 @@ public partial class PasswordInputForm : Form
promptLabel.AutoSize = false;
this.Controls.Add(promptLabel);
- // Password textbox
+ //密码文本框
passwordTextBox = new TextBox();
passwordTextBox.Location = new System.Drawing.Point(12, 55);
passwordTextBox.Size = new System.Drawing.Size(360, 20);
- passwordTextBox.UseSystemPasswordChar = true; // This masks the input
+ passwordTextBox.UseSystemPasswordChar = true; // 这会隐藏输入内容
passwordTextBox.KeyPress += (s, e) =>
{
if (e.KeyChar == (char)Keys.Return)
@@ -99,27 +99,27 @@ public partial class PasswordInputForm : Form
};
this.Controls.Add(passwordTextBox);
- // OK button
+ //确定按钮
okButton = new Button();
- okButton.Text = "OK";
+ okButton.Text = "确定";
okButton.Location = new System.Drawing.Point(216, 85);
okButton.Size = new System.Drawing.Size(150, 50);
okButton.Click += OkButton_Click;
this.Controls.Add(okButton);
- // Cancel button
+ //取消按钮
cancelButton = new Button();
- cancelButton.Text = "Cancel";
+ cancelButton.Text = "取消";
cancelButton.Location = new System.Drawing.Point(297, 85);
cancelButton.Size = new System.Drawing.Size(150, 50);
cancelButton.Click += CancelButton_Click;
this.Controls.Add(cancelButton);
- // Set default and cancel buttons
+ //设置默认按钮和取消按钮
this.AcceptButton = okButton;
this.CancelButton = cancelButton;
- // Focus on textbox when form loads
+ //窗体加载时将焦点置于文本框
this.Load += (s, e) => passwordTextBox.Focus();
}
@@ -178,7 +178,7 @@ public static class MaskedInputHelper
};
var buttonOk = new Button()
{
- Text = "OK",
+ Text = "确定",
Size = new System.Drawing.Size(150, 50),
Left = 12,
Width = 150,
@@ -187,7 +187,7 @@ public static class MaskedInputHelper
};
var buttonCancel = new Button()
{
- Text = "Cancel",
+ Text = "取消",
Size = new System.Drawing.Size(150, 50),
Left = 175,
Width = 150,
@@ -211,7 +211,7 @@ public static class MaskedInputHelper
}
}
-//Code to retrieve Databricks Connection information from the M Query in a table partition
+//从表分区中的 M 查询检索 Databricks 连接信息的代码
public class DatabricksConnectionInfo
{
public string ServerHostname { get; set; }
@@ -222,11 +222,11 @@ public class DatabricksConnectionInfo
public override string ToString()
{
- return $"Server: {ServerHostname}\n"
- + $"HTTP Path: {HttpPath}\n"
- + $"Database: {DatabaseName}\n"
- + $"Schema: {SchemaName}\n"
- + $"Table: {TableName}";
+ return $"服务器:{ServerHostname}\n"
+ + $"HTTP 路径:{HttpPath}\n"
+ + $"数据库:{DatabaseName}\n"
+ + $"架构:{SchemaName}\n"
+ + $"表:{TableName}";
}
}
@@ -235,35 +235,35 @@ public class PowerQueryMParser
public static DatabricksConnectionInfo ParseMQuery(string mQuery)
{
if (string.IsNullOrWhiteSpace(mQuery))
- throw new ArgumentException("M query cannot be null or empty");
+ throw new ArgumentException("M 查询不能为空或空字符串");
var connectionInfo = new DatabricksConnectionInfo();
try
{
- // Parse Source line to extract server hostname and HTTP path
+ //解析 Source 行以提取服务器主机名和 HTTP 路径
ParseSourceLine(mQuery, connectionInfo);
- // Parse Database line to extract database name
+ //解析 Database 行以提取数据库名称
ParseDatabaseLine(mQuery, connectionInfo);
- // Parse Schema line to extract schema name
+ //解析 Schema 行以提取架构名称
ParseSchemaLine(mQuery, connectionInfo);
- // Parse Data line to extract table name
+ //解析 Data 行以提取表名
ParseDataLine(mQuery, connectionInfo);
return connectionInfo;
}
catch (Exception ex)
{
- throw new InvalidOperationException($"Error parsing M query: {ex.Message}", ex);
+ throw new InvalidOperationException($"解析 M 查询时出错:{ex.Message}", ex);
}
}
private static void ParseSourceLine(string mQuery, DatabricksConnectionInfo connectionInfo)
{
- // Pattern to match both:
+ //匹配以下两种模式:
// Source = DatabricksMultiCloud.Catalogs("hostname", "httppath", null),
// Source = Databricks.Catalogs("hostname", "httppath", null),
var sourcePattern =
@@ -276,7 +276,7 @@ public class PowerQueryMParser
if (!sourceMatch.Success)
throw new FormatException(
- "Could not find valid Source definition in M query (supports both Databricks and DatabricksMultiCloud connectors)"
+ "在 M 查询中找不到有效的 Source 定义(同时支持 Databricks 和 DatabricksMultiCloud 连接器)"
);
connectionInfo.ServerHostname = sourceMatch.Groups[1].Value;
@@ -285,7 +285,7 @@ public class PowerQueryMParser
private static void ParseDatabaseLine(string mQuery, DatabricksConnectionInfo connectionInfo)
{
- // Pattern to match: Database = Source{[Name="databasename",Kind="Database"]}[Data],
+ //匹配模式:Database = Source{[Name="databasename",Kind="Database"]}[Data],
var databasePattern =
@"Database\s*=\s*Source\s*{\s*\[\s*Name\s*=\s*""([^""]+)""\s*,\s*Kind\s*=\s*""Database""\s*\]\s*}\s*\[\s*Data\s*\]";
var databaseMatch = Regex.Match(
@@ -295,14 +295,14 @@ public class PowerQueryMParser
);
if (!databaseMatch.Success)
- throw new FormatException("Could not find valid Database definition in M query");
+ throw new FormatException("在 M 查询中找不到有效的 Database 定义");
connectionInfo.DatabaseName = databaseMatch.Groups[1].Value;
}
private static void ParseSchemaLine(string mQuery, DatabricksConnectionInfo connectionInfo)
{
- // Pattern to match: Schema = Database{[Name="schemaname",Kind="Schema"]}[Data],
+ //匹配模式:Schema = Database{[Name="schemaname",Kind="Schema"]}[Data],
var schemaPattern =
@"Schema\s*=\s*Database\s*{\s*\[\s*Name\s*=\s*""([^""]+)""\s*,\s*Kind\s*=\s*""Schema""\s*\]\s*}\s*\[\s*Data\s*\]";
var schemaMatch = Regex.Match(
@@ -312,14 +312,14 @@ public class PowerQueryMParser
);
if (!schemaMatch.Success)
- throw new FormatException("Could not find valid Schema definition in M query");
+ throw new FormatException("在 M 查询中找不到有效的 Schema 定义");
connectionInfo.SchemaName = schemaMatch.Groups[1].Value;
}
private static void ParseDataLine(string mQuery, DatabricksConnectionInfo connectionInfo)
{
- // Pattern to match: Data = Schema{[Name="tablename",Kind="Table"]}[Data]
+ //匹配模式:Data = Schema{[Name="tablename",Kind="Table"]}[Data]
var dataPattern =
@"Data\s*=\s*Schema\s*{\s*\[\s*Name\s*=\s*""([^""]+)""\s*,\s*Kind\s*=\s*""Table""\s*\]\s*}\s*\[\s*Data\s*\]";
var dataMatch = Regex.Match(
@@ -329,70 +329,70 @@ public class PowerQueryMParser
);
if (!dataMatch.Success)
- throw new FormatException("Could not find valid Data definition in M query");
+ throw new FormatException("在 M 查询中找不到有效的 Data 定义");
connectionInfo.TableName = dataMatch.Groups[1].Value;
}
}
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
-//main script
+//主脚本
-//check that user has a table selected
+//检查你是否已选择表
if (Selected.Tables.Count == 0)
{
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
- Interaction.MsgBox("Select one or more tables", MsgBoxStyle.Critical, "Table Required");
+ Interaction.MsgBox("请选择一个或多个表", MsgBoxStyle.Critical, "需要选择表");
return;
}
-//prompt for personal access token - required to authenticate to Databricks
+//提示输入个人访问令牌 - 这是连接 Databricks 进行身份验证所必需的
string dbxPAT;
do
{
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
dbxPAT = MaskedInputHelper.GetMaskedInput(
- "Please enter your Databricks Personal Access Token (needed to connect to the SQL Endpoint)",
- "Personal Access Token"
+ "请输入你的 Databricks 个人访问令牌(连接到 SQL 终结点时需要)",
+ "个人访问令牌"
);
if (string.IsNullOrEmpty(dbxPAT))
{
- return; // User cancelled
+ return; // 你已取消
}
if (string.IsNullOrWhiteSpace(dbxPAT))
{
MessageBox.Show(
- "Personal Access Token required",
- "Personal Access Token required",
+ "需要提供个人访问令牌",
+ "需要提供个人访问令牌",
MessageBoxButtons.OK,
MessageBoxIcon.Warning
);
}
} while (string.IsNullOrWhiteSpace(dbxPAT));
-// toggle the 'Running Macro' spinbox
+//切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = true;
-//for each selected table, get the Databricks connection info from the partition info
+//对每个选中的表,从分区信息中获取 Databricks 连接信息
foreach (var t in Selected.Tables)
{
string mQuery = t.Partitions[t.Name].Expression;
var connectionInfo = PowerQueryMParser.ParseMQuery(mQuery);
var columnDescriptions = 0;
var tableDescriptions = 0;
- // Access individual components
+ //访问各个部分
string serverHostname = connectionInfo.ServerHostname;
string httpPath = connectionInfo.HttpPath;
string databaseName = connectionInfo.DatabaseName;
string schemaName = connectionInfo.SchemaName;
string tableName = connectionInfo.TableName;
- //set DBX connection string
+ //设置 DBX 连接字符串
var odbcConnStr =
@"DSN=Simba Spark;driver=C:\Program Files\Simba Spark ODBC Driver;host="
+ serverHostname
@@ -401,7 +401,7 @@ foreach (var t in Selected.Tables)
+ ";thrifttransport=2;ssl=1;authmech=3;uid=token;pwd="
+ dbxPAT;
- //test connection
+ //测试连接
OdbcConnection conn = new OdbcConnection(odbcConnStr);
try
{
@@ -409,34 +409,34 @@ foreach (var t in Selected.Tables)
}
catch
{
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
Interaction.MsgBox(
- @"Connection failed
+ @"连接失败
-Please check the following prequisites:
+请确认以下几点:
-- you must have the Simba Spark ODBC Driver installed
-(download from https://www.databricks.com/spark/odbc-drivers-download)
+- 你需要先安装 Simba Spark ODBC Driver
+(可从 https://www.databricks.com/spark/odbc-drivers-download 下载)
-- the ODBC driver must be installed in the path C:\Program Files\Simba Spark ODBC Driver
+- ODBC 驱动程序必须安装在路径 C:\Program Files\Simba Spark ODBC Driver 中
-- check that the Databricks server name "
+- 请检查 Databricks 服务器名称 "
+ serverHostname
- + @" is correct
+ + @" 是否正确
-- check that the Databricks SQL endpoint / HTTP Path "
+- 请检查 Databricks SQL 终结点 / HTTP 路径 "
+ httpPath
- + @" is correct
+ + @" 是否正确
-- check that you have used a valid Personal Access Token",
+- 请检查你使用的是有效的个人访问令牌",
MsgBoxStyle.Critical,
- "Connection Error"
+ "连接错误"
);
return;
}
- //get table metadata
+ //获取表元数据
var tableQuery =
"SELECT comment FROM "
+ databaseName
@@ -454,24 +454,24 @@ Please check the following prequisites:
}
catch
{
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
Interaction.MsgBox(
- @"Connection failed
+ @"连接失败
-Either:
- - the table "
+可能是以下原因:
+ - 表 "
+ schemaName
+ "."
+ tableName
- + " does not exist"
+ + " 不存在"
+ @"
- - you do not have permissions to query this table
+ - 你没有权限查询此表
- - the connection timed out. Please check that the SQL Endpoint cluster is running",
+ - 连接超时。请检查 SQL 终结点群集是否正在运行",
MsgBoxStyle.Critical,
- "Connection Error - Table Metadata"
+ "连接错误 - 表元数据"
);
return;
}
@@ -481,11 +481,11 @@ Either:
if (t.Description != row["comment"].ToString())
{
t.Description = row["comment"].ToString();
- tableUpdate = t.Name + " table description updated.";
+ tableUpdate = t.Name + " 的表说明已更新。";
}
}
- //get column metadata
+ //获取列元数据
var columnsQuery = @"DESCRIBE " + databaseName + "." + schemaName + "." + tableName;
OdbcDataAdapter da = new OdbcDataAdapter(columnsQuery, conn);
var dbxColumns = new sysData.DataTable();
@@ -496,29 +496,29 @@ Either:
}
catch
{
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
Interaction.MsgBox(
- @"Connection failed
+ @"连接失败
-Either:
- - the table "
+可能是以下原因:
+ - 表 "
+ schemaName
+ "."
+ tableName
- + " does not exist"
+ + " 不存在"
+ @"
- - you do not have permissions to query this table
+ - 你没有权限查询此表
- - the connection timed out. Please check that the SQL Endpoint cluster is running",
+ - 连接超时。请检查 SQL 终结点群集是否正在运行",
MsgBoxStyle.Critical,
- "Connection Error - Column Metadata"
+ "连接错误 - 列元数据"
);
return;
}
- //update column descriptions
+ //更新列说明
int counter = 0;
foreach (sysData.DataRow row in dbxColumns.Rows)
{
@@ -542,19 +542,20 @@ Either:
tableUpdate
+ @"
-"
+已更新 "
+ + t.Name
+ + " 中的 "
+ counter
- + " descriptions updated on "
- + t.Name;
+ + " 个说明";
}
else
{
- msg = counter + " descriptions updated on " + t.Name;
+ msg = "已更新 " + t.Name + " 中的 " + counter + " 个说明";
}
- // toggle the 'Running Macro' spinbox
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = false;
- Interaction.MsgBox(msg, MsgBoxStyle.Information, "Update Metadata Descriptions");
- // toggle the 'Running Macro' spinbox
+ Interaction.MsgBox(msg, MsgBoxStyle.Information, "更新元数据说明");
+ //切换“正在运行宏”指示器
ScriptHelper.WaitFormVisible = true;
conn.Close();
}
@@ -562,16 +563,16 @@ Either:
### 说明
-脚本使用 WinForms 提示输入 Databricks 个人访问令牌,用于对 Databricks 进行身份验证。 对于每个选中的表,脚本会从该表分区的 M 查询中提取 Databricks 连接字符串信息,以及架构名和表名。 然后脚本通过 Spark ODBC 驱动向 Databricks 发送 SQL 查询,查询 information_schema 表,返回在 Unity Catalog 中定义的表描述。 随后会将该描述更新到语义模型中的表描述。 脚本还会对所选表发送第二个使用 DESCRIBE 命令的 SQL 查询,以获取列描述。 这些结果会被循环遍历,并在模型中添加描述。 脚本在每个选定表上运行完成后,会显示一个对话框,告知已更新的描述数量。
+该脚本使用 WinForms 弹窗提示输入 Databricks 个人访问令牌,用于对 Databricks 进行身份验证。 对每个选中的表,脚本都会从其分区中的 M 查询提取 Databricks 连接字符串信息,以及架构名和表名。 随后脚本会通过 Spark ODBC 驱动程序向 Databricks 发送 SQL 查询,查询 information_schema 表,从而获取 Unity Catalog 中定义的表说明。 然后会将其更新到语义模型中的表说明。 还会对所选表再发送一条使用 DESCRIBE 命令的 SQL 查询,以获取列说明。 随后会遍历这些结果,并在模型中补充说明。 脚本在每个选定的表上运行完毕后,会弹出对话框,显示已更新的描述数量。
## 输出示例
-  图 1:脚本会提示你输入 Databricks 个人访问令牌,以便向 Databricks 验证身份。
+ 图 1:脚本会提示你输入 Databricks 个人访问令牌,以便向 Databricks 进行身份验证。
-
图 1:脚本会提示你输入 Databricks 个人访问令牌,以便向 Databricks 验证身份。
+ 图 1:脚本会提示你输入 Databricks 个人访问令牌,以便向 Databricks 进行身份验证。
-  图 2:脚本在每个选定表上运行完成后,会显示已更新的描述条数。
+ 图 2:脚本对每个选定的表运行完毕后,会显示已更新的描述数量。
diff --git a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
index b8e0aaed..4e525ce9 100644
--- a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
+++ b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
@@ -1,6 +1,6 @@
---
uid: script-convert-dlol-to-import
-title: 将 OneLake 上的 Direct Lake 转换为导入模式
+title: 将 OneLake 上的 Direct Lake 表转换为导入模式
author: Morten Lønskov
updated: 2025-06-25
applies_to:
@@ -15,11 +15,11 @@ applies_to:
## 脚本用途
-此脚本将 OneLake 上的 Direct Lake(DL/OL)转换为导入模式表。 正如 [Direct Lake guidance article](xref:direct-lake-guidance) 中所述,我们需要将这类表上的 [EntityPartition](https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.entitypartitionsource?view=analysisservices-dotnet) 替换为导入模式下对应的常规 M 分区。
+此脚本用于将 OneLake 上的 Direct Lake(DL/OL)表转换为导入模式表。 如 [Direct Lake 指南文章](xref:direct-lake-guidance) 中所述,我们需要将此类表上的 [EntityPartition](https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.entitypartitionsource?view=analysisservices-dotnet) 替换为导入模式下相应的常规 M 分区。
-## 先决条件
+## 前提条件
-你需要 **SQL Endpoint**,以及 Fabric Warehouse 或 Lakehouse 的 **名称**。 两者都可以在 Fabric 门户中找到。
+你需要 **SQL Endpoint**,以及 Fabric **Warehouse** 或 **Lakehouse** 的 **名称**。 这两项都可以在 Fabric 门户中找到。
你还需要知道要连接的表/物化视图的 **Schema**。 对于 Lakehouse,默认值为 dbo。
@@ -31,8 +31,8 @@ applies_to:
// ===================================================================================
// 将 OneLake 上的 Direct Lake 表转换回导入模式
// ----------------------------------------
-// 此脚本会将选中的表或所有表从 OneLake 上的 Direct Lake 转换为导入模式
-// 它会添加名为 SQLEndpoint 的共享表达式,并在不再需要时删除现有的 DatabaseQuery
+// 此脚本会将选定的表或所有表从 OneLake 上的 Direct Lake 转换为导入模式
+// 它会添加一个名为 SQLEndpoint 的共享表达式,并在不再需要时删除现有的 DatabaseQuery
// ===================================================================================
using System;
using System.Linq;
@@ -62,7 +62,7 @@ public class ScopeSelectionDialog : Form
Controls.Add(layout);
layout.Controls.Add(new Label {
- Text = $"你已选择 {selectedCount} 个表,\n模型中共有 {totalCount} 个 Direct Lake 表。",
+ Text = $"你已选择 {selectedCount} 个表(s),\n并且模型中共有 {totalCount} 个 Direct Lake 表(s)。",
AutoSize = true, TextAlign = ContentAlignment.MiddleLeft
});
@@ -73,7 +73,7 @@ public class ScopeSelectionDialog : Form
};
var btnOnly = new Button {
- Text = "仅转换所选表", AutoSize = true,
+ Text = "仅选定的表", AutoSize = true,
DialogResult = DialogResult.OK
};
btnOnly.Click += (s, e) => SelectedOption = ScopeOption.OnlySelected;
@@ -99,7 +99,7 @@ public class ScopeSelectionDialog : Form
}
// -------------------------------------------------------------------
-// 2) SQL 导入对话框(现在需要 Schema)
+// 2) SQL 导入对话框(现需 Schema)
// -------------------------------------------------------------------
public class SqlImportDialog : Form
{
@@ -110,7 +110,7 @@ public class SqlImportDialog : Form
public SqlImportDialog(string endpoint, string db, string schema)
{
- Text = "转换 Direct Lake → 导入";
+ Text = "转换 Direct Lake → Import";
AutoSize = true; AutoSizeMode = AutoSizeMode.GrowAndShrink;
StartPosition = FormStartPosition.CenterParent;
Padding = new Padding(20);
@@ -162,7 +162,7 @@ public class SqlImportDialog : Form
AcceptButton = okButton;
CancelButton = cancel;
- // 仅当三个字段都非空时才启用 OK
+ // 仅当这三个字段都非空时才启用“OK”
SqlEndpoint.TextChanged += Validate;
DatabaseName.TextChanged += Validate;
Schema.TextChanged += Validate;
@@ -191,7 +191,7 @@ var allDirectLake = Model.Tables
&& t.Partitions[0].Mode == ModeType.DirectLake)
.ToList();
-// 3.2) 以及你已选择的 Direct Lake 表
+// 3.2) 以及你选中的表
var selectedDirect = Selected.Tables
.Cast
图 2:脚本在每个选定表上运行完成后,会显示已更新的描述条数。
+ 图 2:脚本对每个选定的表运行完毕后,会显示已更新的描述数量。
diff --git a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
index b8e0aaed..4e525ce9 100644
--- a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
+++ b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlol-to-import.md
@@ -1,6 +1,6 @@
---
uid: script-convert-dlol-to-import
-title: 将 OneLake 上的 Direct Lake 转换为导入模式
+title: 将 OneLake 上的 Direct Lake 表转换为导入模式
author: Morten Lønskov
updated: 2025-06-25
applies_to:
@@ -15,11 +15,11 @@ applies_to:
## 脚本用途
-此脚本将 OneLake 上的 Direct Lake(DL/OL)转换为导入模式表。 正如 [Direct Lake guidance article](xref:direct-lake-guidance) 中所述,我们需要将这类表上的 [EntityPartition](https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.entitypartitionsource?view=analysisservices-dotnet) 替换为导入模式下对应的常规 M 分区。
+此脚本用于将 OneLake 上的 Direct Lake(DL/OL)表转换为导入模式表。 如 [Direct Lake 指南文章](xref:direct-lake-guidance) 中所述,我们需要将此类表上的 [EntityPartition](https://learn.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.entitypartitionsource?view=analysisservices-dotnet) 替换为导入模式下相应的常规 M 分区。
-## 先决条件
+## 前提条件
-你需要 **SQL Endpoint**,以及 Fabric Warehouse 或 Lakehouse 的 **名称**。 两者都可以在 Fabric 门户中找到。
+你需要 **SQL Endpoint**,以及 Fabric **Warehouse** 或 **Lakehouse** 的 **名称**。 这两项都可以在 Fabric 门户中找到。
你还需要知道要连接的表/物化视图的 **Schema**。 对于 Lakehouse,默认值为 dbo。
@@ -31,8 +31,8 @@ applies_to:
// ===================================================================================
// 将 OneLake 上的 Direct Lake 表转换回导入模式
// ----------------------------------------
-// 此脚本会将选中的表或所有表从 OneLake 上的 Direct Lake 转换为导入模式
-// 它会添加名为 SQLEndpoint 的共享表达式,并在不再需要时删除现有的 DatabaseQuery
+// 此脚本会将选定的表或所有表从 OneLake 上的 Direct Lake 转换为导入模式
+// 它会添加一个名为 SQLEndpoint 的共享表达式,并在不再需要时删除现有的 DatabaseQuery
// ===================================================================================
using System;
using System.Linq;
@@ -62,7 +62,7 @@ public class ScopeSelectionDialog : Form
Controls.Add(layout);
layout.Controls.Add(new Label {
- Text = $"你已选择 {selectedCount} 个表,\n模型中共有 {totalCount} 个 Direct Lake 表。",
+ Text = $"你已选择 {selectedCount} 个表(s),\n并且模型中共有 {totalCount} 个 Direct Lake 表(s)。",
AutoSize = true, TextAlign = ContentAlignment.MiddleLeft
});
@@ -73,7 +73,7 @@ public class ScopeSelectionDialog : Form
};
var btnOnly = new Button {
- Text = "仅转换所选表", AutoSize = true,
+ Text = "仅选定的表", AutoSize = true,
DialogResult = DialogResult.OK
};
btnOnly.Click += (s, e) => SelectedOption = ScopeOption.OnlySelected;
@@ -99,7 +99,7 @@ public class ScopeSelectionDialog : Form
}
// -------------------------------------------------------------------
-// 2) SQL 导入对话框(现在需要 Schema)
+// 2) SQL 导入对话框(现需 Schema)
// -------------------------------------------------------------------
public class SqlImportDialog : Form
{
@@ -110,7 +110,7 @@ public class SqlImportDialog : Form
public SqlImportDialog(string endpoint, string db, string schema)
{
- Text = "转换 Direct Lake → 导入";
+ Text = "转换 Direct Lake → Import";
AutoSize = true; AutoSizeMode = AutoSizeMode.GrowAndShrink;
StartPosition = FormStartPosition.CenterParent;
Padding = new Padding(20);
@@ -162,7 +162,7 @@ public class SqlImportDialog : Form
AcceptButton = okButton;
CancelButton = cancel;
- // 仅当三个字段都非空时才启用 OK
+ // 仅当这三个字段都非空时才启用“OK”
SqlEndpoint.TextChanged += Validate;
DatabaseName.TextChanged += Validate;
Schema.TextChanged += Validate;
@@ -191,7 +191,7 @@ var allDirectLake = Model.Tables
&& t.Partitions[0].Mode == ModeType.DirectLake)
.ToList();
-// 3.2) 以及你已选择的 Direct Lake 表
+// 3.2) 以及你选中的表
var selectedDirect = Selected.Tables
.Cast()
.Where(t => t.Partitions.Count == 1
@@ -199,7 +199,7 @@ var selectedDirect = Selected.Tables
&& t.Partitions[0].Mode == ModeType.DirectLake)
.ToList();
-// 3.3) 询问范围
+// 3.3) 询问转换范围
var scopeDialog = new ScopeSelectionDialog(selectedDirect.Count, allDirectLake.Count);
var dr = scopeDialog.ShowDialog();
if (dr == DialogResult.Cancel || scopeDialog.SelectedOption == ScopeSelectionDialog.ScopeOption.Cancel)
@@ -216,11 +216,11 @@ if (tablesToConvert.Count == 0)
return;
}
-// 3.4) 询问连接信息 + Schema
+// 3.4) 询问连接信息和 Schema
var sqlDialog = new SqlImportDialog("", "", "");
if (sqlDialog.ShowDialog() == DialogResult.Cancel) return;
-// 3.5) 新增或更新共享表达式 "SQLEndpoint"
+// 3.5) 创建或更新共享表达式 "SQLEndpoint"
const string sqlTemplate = @"let
endpoint = Sql.Database(""{0}"",""{1}"")
in
@@ -253,33 +253,33 @@ foreach (var table in tablesToConvert)
oldP.Delete();
}
-// 3.8) 如果转换的是**整个模型**,删除旧的 DatabaseQuery 表达式
+// 3.8) 如果转换的是**整个模型**,则删除旧的 DatabaseQuery 表达式
if (isAllTables)
{
var oldDbq = Model.Expressions.FirstOrDefault(e => e.Name == "DatabaseQuery");
if (oldDbq != null)
- oldDbq.Delete(); // TE3 API: Expression.Delete() removes it from the model
+ oldDbq.Delete(); // TE3 API:Expression.Delete() 会将其从模型中移除
}
-// 3.9) 确保默认模式为导入模式
+// 3.9) 确保默认模式为 Import
Model.DefaultMode = ModeType.Import;
-Info("转换完成:Direct Lake → 导入" +
- (isAllTables ? " (已删除 DatabaseQuery)" : "") + "。");
+Info("转换完成:Direct Lake → Import" +
+ (isAllTables ? " (DatabaseQuery 已移除)" : "") + ".");
```
### 说明
-脚本会先提示你选择转换范围:只转换所选表,或转换模型中的所有表。 然后,它会识别在所选范围内当前处于 Direct Lake 模式的表。 如果没找到符合条件的表,或者你取消了对话框,脚本就会停止运行。
+脚本首先会提示你确定转换范围:是只转换选定的表,还是转换模型中的所有表。 然后,脚本会识别所选范围内当前处于 Direct Lake 模式的表。 如果没找到适用的表,或者你取消了对话框,脚本就会终止。
-接着会提示你输入 SQL analytics endpoint、Lakehouse 或 Warehouse 的名称,以及必填的 Schema 名称。 脚本会确保这三个字段均已填写后,才允许你继续。
+接着,脚本会提示你输入 SQL analytics endpoint、Lakehouse 或 Warehouse 的名称,以及必填的 Schema 名称。 脚本会确保这三个字段都已填写后,才允许你继续。
-接下来,脚本会使用你提供的连接信息创建或更新名为 `SQLEndpoint` 的共享表达式。 该表达式使用 `Sql.Database` 连接器来访问 Lakehouse 或 Warehouse。
+接下来,脚本会使用提供的连接详细信息创建或更新一个名为 `SQLEndpoint` 的共享表达式。 此表达式使用 `Sql.Database` 连接器访问 Lakehouse 或 Warehouse。
-对于每个要转换的表,脚本会创建一个新的导入模式 M 分区:引用 `SQLEndpoint` 表达式,并使用指定的 Schema 和表名。 现有的 Direct Lake 分区会先被重命名,然后删除,最终仅保留新的导入分区。
+对于每个要转换的表,脚本都会创建一个新的导入模式 M 分区,该分区引用 `SQLEndpoint` 表达式,并使用指定的 Schema 和表名。 现有的 Direct Lake 分区会先被重命名,然后被删除,最终只保留新的导入分区。
-最后,如果你选择转换模型中的所有 Direct Lake 表,脚本会检查是否存在名为 `DatabaseQuery` 的共享表达式;若存在则删除。 然后把模型的默认存储模式设置为导入模式,并显示一条确认信息。
+最后,如果你选择转换模型中的所有 Direct Lake 表,脚本会检查是否存在名为 `DatabaseQuery` 的共享表达式;如果存在,就将其删除。 随后,模型的默认存储模式会设置为导入模式,并显示确认信息。
-## AI 使用免责声明
+## AI 使用声明
-此脚本在 LLM 的帮助下创建。
+此脚本在大语言模型的协助下创建。
diff --git a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlsql-to-dlol.md b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlsql-to-dlol.md
index dc7bb2ae..e0465c83 100644
--- a/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlsql-to-dlol.md
+++ b/localizedContent/zh/content/features/CSharpScripts/Advanced/script-convert-dlsql-to-dlol.md
@@ -1,6 +1,6 @@
---
uid: script-convert-dlsql-to-dlol
-title: 将 Direct Lake on SQL 转换为 OneLake
+title: 将 SQL 上的 Direct Lake 转换到 OneLake
author: Daniel Otykier
updated: 2025-06-20
applies_to:
@@ -11,7 +11,7 @@ applies_to:
full: true
---
-# 将 Direct Lake on SQL 转换为 OneLake
+# 将 SQL 上的 Direct Lake 转换到 OneLake
## 脚本用途
diff --git a/localizedContent/zh/content/features/CSharpScripts/csharp-script-library-advanced.md b/localizedContent/zh/content/features/CSharpScripts/csharp-script-library-advanced.md
index 3591fe0f..8ac20578 100644
--- a/localizedContent/zh/content/features/CSharpScripts/csharp-script-library-advanced.md
+++ b/localizedContent/zh/content/features/CSharpScripts/csharp-script-library-advanced.md
@@ -1,6 +1,6 @@
---
uid: script-library-advanced
-title: 高级 C# 脚本
+title: 高级 C# Script
author: Morten Lønskov
updated: 2026-02-20
applies_to:
@@ -11,27 +11,27 @@ applies_to:
full: true
---
-# C# Script 库: 高级脚本
+# C# Script 库:高级脚本
-这些脚本更高级,功能更复杂,需要对 C# 语言和 TOM 有更深入的理解。 它们更难修改,因此建议在你已熟悉 Tabular Editor 中 C# Script 的基础之后再使用。
+这些脚本更加高级,功能也更复杂,需要对 C# 语言和 TOM 有更深入的理解。 这些脚本更难修改,因此建议你在熟悉 Tabular Editor 中的 C# Script 基础后再使用。
-| 脚本名称
| 用途 | 使用场景 |
-| ----------------------------------------------------------------------- | ------------------------------------------------------------------------ | ------------------------------------------------------ |
-| [统计模型对象](xref:script-count-things) | 按类型统计模型中各类对象的数量。 | 当你需要概览模型内容,或想按类型统计对象数量时。 |
-| [在网格中输出对象详细信息](xref:script-output-things) | 以网格视图输出对象详细信息。 | 当你需要在网格视图中输出对象详细信息以便检查时。 |
-| [创建日期表](xref:script-create-date-table) | 基于模型中选定的日期列创建格式化的日期表。 | 当你需要基于模板创建新的日期表时。 |
-| [创建 M 参数(自动替换)](xref:script-create-and-replace-parameter) | 创建新的 M 参数,并自动将其添加到 M 分区。 | 当你想用动态 M 参数替换多个分区中的字符串(例如连接字符串)时。 |
-| [格式化 Power Query](xref:script-format-power-query) | 使用 powerqueryformatter.com API 格式化所选 M 分区中的 Power Query。 | 当 Power Query 很复杂,需要提高可读性以便阅读或修改时。 |
-| [实施增量刷新](xref:script-implement-incremental-refresh) | 通过 UI 对话框中的参数自动配置增量刷新。 | 当你需要实施增量刷新,但不太熟悉表设置中的配置方式时。 |
-| [删除包含错误的度量值](xref:script-remove-measures-with-error) | 创建新的 M 参数,并自动将其添加到 M 分区。 | 当你想用动态 M 参数替换多个分区中的字符串(例如连接字符串)时。 |
-| [在所选度量值中查找/替换](xref:script-find-replace) | 在所选度量值的 DAX 中搜索子字符串,并替换为另一个子字符串。 | 当你需要在多个 DAX 度量值中快速查找/替换值时(例如 `CALCULATE` 筛选器或失效的对象引用)。 |
-| [Databricks 语义模型设置](xref:script-databricks-semantic-model-set-up) | 为表和列指定友好名称,并设置列最佳实践 | 当你需要让 Databricks 对象名称更便于用户理解时。 |
-| [创建 Databricks 关系](xref:script-create-databricks-relationships) | 基于 Databricks Unity Catalog 中的主键和外键定义创建关系 | 当你想复用 Unity Catalog 中已定义的 Databricks 关系时。 |
-| [添加 Databricks 元数据说明](xref:script-add-databricks-metadata-descriptions) | 基于 Databricks Unity Catalog 更新表和列说明 | 当你想复用 Unity Catalog 中已定义的 Databricks 表和列注释时。 |
-| [将 DL/SQL 转换为 DL/OL](xref:script-convert-dlsql-to-dlol) | 将 Direct Lake over SQL 模型的分区更改为 Direct Lake over OneLake | 可用于轻松迁移到 Direct Lake over OneLake |
-| [将导入模式转换为 DL/OL](xref:script-convert-import-to-dlol) | 将 Import 模型的分区更改为基于 OneLake 的 Direct Lake | 有助于轻松迁移到基于 OneLake 的 Direct Lake |
-| [将 DL/OL 转换为导入模式](xref:script-convert-dlol-to-import) | 将 OneLake 上的 Direct Lake 模型分区切换到导入模式 | 便于从 OneLake 上的 Direct Lake 模式轻松迁移到导入模式 |
-| [实现用户定义的聚合](xref:script-implement-user-defined-aggregations) | 自动为所选事实表配置用户定义的聚合。 | 当需要实现用户定义的聚合模式,但又不想手动执行每个配置步骤时。 |
\ No newline at end of file
+| 脚本名称
| 用途 | 适用场景 |
+| ---------------------------------------------------------------------------------------- | ----------------------------------------------------------------------- | ------------------------------------------------------ |
+| [统计模型对象数量](xref:script-count-things) | 统计模型中各类对象的数量。 | 当你需要概览模型内容,或需要按类型统计对象数量时。 |
+| [在网格中输出对象详细信息](xref:script-output-things) | 在网格视图中输出对象详细信息。 | 当你需要在网格视图中输出对象详细信息以便检查时。 |
+| [创建日期表](xref:script-create-date-table) | 根据模型中选定的日期列创建带格式的日期表。 | 当你需要基于模板创建新的日期表时。 |
+| [创建 M 参数(自动替换)](xref:script-create-and-replace-parameter) | 创建新的 M 参数,并自动将其添加到 M 分区中。 | 当你想用动态 M 参数替换多个分区中的字符串(例如连接字符串)时。 |
+| [格式化 Power Query](xref:script-format-power-query) | 使用 powerqueryformatter.com API 格式化所选 M 分区的 Power Query。 | 当 Power Query 很复杂,需要让它更便于阅读或修改时。 |
+| [实现增量刷新](xref:script-implement-incremental-refresh) | 使用 UI 对话框中的参数自动配置增量刷新。 | 当你需要实现增量刷新,但不太熟悉表设置中的相关配置时。 |
+| [删除出错的度量值](xref:script-remove-measures-with-error) | 创建新的 M 参数,并自动将其添加到 M 分区。 | 当你想用动态 M 参数替换多个分区中的字符串(例如连接字符串)时。 |
+| [在所选度量值中查找/替换](xref:script-find-replace) | 在所选度量值的 DAX 中搜索子字符串,并将其替换为另一个子字符串。 | 当你需要在多个 DAX 度量值中快速查找/替换值时(例如 `CALCULATE` 筛选器或无效的对象引用)。 |
+| [设置 Databricks 语义模型](xref:script-databricks-semantic-model-set-up) | 为表和列设置更友好的名称,并应用列最佳实践 | 当需要让 Databricks 对象名称更友好、更易读时。 |
+| [创建 Databricks 关系](xref:script-create-databricks-relationships) | 根据 Databricks Unity Catalog 中的主键和外键定义创建关系 | 当你想复用已在 Unity Catalog 中定义的 Databricks 关系时。 |
+| [添加 Databricks 元数据描述](xref:script-add-databricks-metadata-descriptions) | 根据 Databricks Unity Catalog 更新表和列的描述 | 当你想重用已在 Unity Catalog 中定义的 Databricks 表和列注释时。 |
+| [将 Direct Lake over SQL 转换为 Direct Lake over OneLake](xref:script-convert-dlsql-to-dlol) | 将 Direct Lake over SQL 模型的分区更改为 Direct Lake over OneLake | 适用于轻松迁移到 Direct Lake over OneLake |
+| [将导入模式转换为 DL/OL](xref:script-convert-import-to-dlol) | 将导入模式模型的分区更改为 Direct Lake over OneLake | 便于轻松迁移到 OneLake 上的 Direct Lake |
+| [将 DL/OL 转换为导入模式](xref:script-convert-dlol-to-import) | 将 OneLake 上的 Direct Lake 模型分区切换为导入模式 | 便于轻松从 OneLake 上的 Direct Lake 迁移到导入模式 |
+| [实现用户自定义聚合](xref:script-implement-user-defined-aggregations) | 自动为所选事实表配置用户自定义聚合。 | 当您希望在不手动执行每个配置步骤的情况下实现用户自定义聚合模式时。 |
\ No newline at end of file
diff --git a/localizedContent/zh/content/features/Semantic-Model/direct-lake-sql-model.md b/localizedContent/zh/content/features/Semantic-Model/direct-lake-sql-model.md
index 9ba53447..66c37b6b 100644
--- a/localizedContent/zh/content/features/Semantic-Model/direct-lake-sql-model.md
+++ b/localizedContent/zh/content/features/Semantic-Model/direct-lake-sql-model.md
@@ -11,7 +11,7 @@ applies_to:
editions:
- edition: Desktop
none: true
- - edition: Business
+ - edition: 商业版
none: true
- edition: Enterprise
full: true
diff --git a/localizedContent/zh/content/features/Useful-script-snippets.md b/localizedContent/zh/content/features/Useful-script-snippets.md
index dc383fb5..1972dfd5 100644
--- a/localizedContent/zh/content/features/Useful-script-snippets.md
+++ b/localizedContent/zh/content/features/Useful-script-snippets.md
@@ -18,16 +18,16 @@ applies_to:
# 实用脚本片段
-这里汇总了一些小脚本片段,帮助你开始使用 Tabular Editor 的 [高级脚本功能](/Advanced-Scripting)。 其中许多脚本都适合保存为 [自定义操作](/Custom-Actions),这样你就能从上下文菜单中轻松重复使用它们。'
+这里汇总了一些简短的脚本片段,帮助你快速上手 Tabular Editor 的 [高级脚本功能](/Advanced-Scripting)。 其中很多脚本都适合保存为 [自定义操作](/Custom-Actions),这样你就可以通过上下文菜单轻松复用它们。'
-另外,也别忘了看看我们的脚本库 @csharp-script-library,里面有更多贴近实战的示例,展示你可以用 Tabular Editor 的脚本能力做些什么。
+另外,也别忘了看看我们的脚本库 @csharp-script-library,里面有更多贴近实际场景的示例,展示了你可以如何利用 Tabular Editor 的脚本功能。
***
## 从列创建度量值
```csharp
-// 为每个当前选中的列创建一个 SUM 度量值,并隐藏该列。
+// 为当前选中的每一列创建一个 SUM 度量值,并隐藏该列。
foreach(var c in Selected.Columns)
{
var newMeasure = c.Table.AddMeasure(
@@ -39,21 +39,21 @@ foreach(var c in Selected.Columns)
// 为新度量值设置格式字符串:
newMeasure.FormatString = "0.00";
- // 提供一些说明文档:
- newMeasure.Description = "此度量值是对列求和 " + c.DaxObjectFullName;
+ // 添加一些说明:
+ newMeasure.Description = "这个度量值是列 " + c.DaxObjectFullName + " 的总和";
- // 隐藏基础列:
+ // 隐藏原始列:
c.IsHidden = true;
}
```
-此片段使用 `.AddMeasure(, , )` 函数,在表上创建一个新的度量值。 我们使用 `DaxObjectFullName` 属性来获取列的完全限定名称,用于 DAX 表达式:`'TableName'[ColumnName]`。
+这个片段使用 `.AddMeasure(, , )` 函数,在表中创建一个新的度量值。 我们使用 `DaxObjectFullName` 属性来获取列的完全限定名称,以便在 DAX 表达式中使用:`'TableName'[ColumnName]`。
***
## 生成时间智能度量值
-首先,为各个时间智能汇总分别创建自定义操作。 例如:
+首先,为各个时间智能聚合分别创建自定义操作。 例如:
```csharp
// 为每个选中的度量值创建一个 TOTALYTD 度量值。
@@ -66,86 +66,86 @@ foreach(var m in Selected.Measures) {
}
```
-这里我们使用 `DaxObjectName` 属性来生成用于 DAX 表达式的非限定引用,因为这是一个度量值:`[MeasureName]`。 将其保存为名为 "Time Intelligence\Create YTD measure" 的自定义操作,并将其应用于度量值。 按同样方式为 MTD、LY,以及你需要的其他项创建操作。 然后,创建下面这个新操作:
+这里我们使用 `DaxObjectName` 属性来生成用于 DAX 表达式的不带限定符的引用,因为这是一个度量值:`[MeasureName]`。 将其保存为一个适用于度量值的时间智能自定义操作,命名为 "Time Intelligence\Create YTD measure"。 为 MTD、LY 以及其他你需要的类型创建类似的操作。 然后,新建一个操作,并填入下面的脚本:
```csharp
-// 调用所有时间智能自定义操作:
-CustomAction(@"Time Intelligence\\Create YTD measure");
-CustomAction(@"Time Intelligence\\Create MTD measure");
-CustomAction(@"Time Intelligence\\Create LY measure");
+// 调用所有时间智能自定义操作:
+CustomAction(@"Time Intelligence\Create YTD measure");
+CustomAction(@"Time Intelligence\Create MTD measure");
+CustomAction(@"Time Intelligence\Create LY measure");
```
-这展示了如何在另一个操作内部执行一个(或多个)自定义操作(注意避免循环引用——这会导致 Tabular Editor 崩溃)。 将其另存为新的自定义操作“时间智能\以上全部”,即可一键生成所有时间智能度量值:
+这展示了如何在一个操作中调用另一个操作来执行一个(或多个)自定义操作(注意避免循环引用,否则会导致 Tabular Editor 崩溃)。 将其另存为新的自定义操作“Time Intelligence\\All of the above”,即可通过一次单击轻松生成所有时间智能度量值:
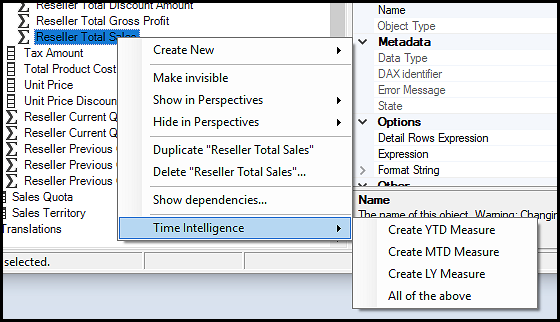
-当然,您也可以将所有时间智能计算放入一个脚本中,如下所示:
+当然,你也可以将所有时间智能计算放入一个脚本中,如下所示:
```csharp
var dateColumn = "'Date'[Date]";
// 为每个所选度量值创建时间智能度量值:
foreach(var m in Selected.Measures) {
- // Year-to-date:
+ // 年初至今:
m.Table.AddMeasure(
- m.Name + " YTD", // Name
- "TOTALYTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX expression
+ m.Name + " YTD", // 名称
+ "TOTALYTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
- // Previous year:
+ // 上年同期:
m.Table.AddMeasure(
- m.Name + " PY", // Name
- "CALCULATE(" + m.DaxObjectName + ", SAMEPERIODLASTYEAR(" + dateColumn + "))", // DAX expression
+ m.Name + " PY", // 名称
+ "CALCULATE(" + m.DaxObjectName + ", SAMEPERIODLASTYEAR(" + dateColumn + "))", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
- // Year-over-year
+ // 同比:
m.Table.AddMeasure(
- m.Name + " YoY", // Name
- m.DaxObjectName + " - [" + m.Name + " PY]", // DAX expression
+ m.Name + " YoY", // 名称
+ m.DaxObjectName + " - [" + m.Name + " PY]", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
- // Year-over-year %:
+ // 同比%:
m.Table.AddMeasure(
- m.Name + " YoY%", // Name
- "DIVIDE([" + m.Name + " YoY], [" + m.Name + " PY])", // DAX expression
+ m.Name + " YoY%", // 名称
+ "DIVIDE([" + m.Name + " YoY], [" + m.Name + " PY])", // DAX 表达式
m.DisplayFolder // 显示文件夹
- ).FormatString = "0.0 %"; // Set format string as percentage
+ ).FormatString = "0.0 %"; // 将格式字符串设置为百分比
- // Quarter-to-date:
+ // 季度至今:
m.Table.AddMeasure(
- m.Name + " QTD", // Name
- "TOTALQTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX expression
+ m.Name + " QTD", // 名称
+ "TOTALQTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
- // Month-to-date:
+ // 本月至今:
m.Table.AddMeasure(
- m.Name + " MTD", // Name
- "TOTALMTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX expression
+ m.Name + " MTD", // 名称
+ "TOTALMTD(" + m.DaxObjectName + ", " + dateColumn + ")", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
}
```
-### 包含其他属性
+### 包含附加属性
-如果您想为新建的度量值设置其他属性,可以将上述脚本修改如下:
+如果你想为新建的度量值设置其他属性,可以将上述脚本修改如下:
```csharp
// 为每个所选度量值创建一个 TOTALYTD 度量值。
foreach(var m in Selected.Measures) {
var newMeasure = m.Table.AddMeasure(
- m.Name + " YTD", // Name
- "TOTALYTD(" + m.DaxObjectName + ", 'Date'[Date])", // DAX expression
+ m.Name + " YTD", // 名称
+ "TOTALYTD(" + m.DaxObjectName + ", 'Date'[Date])", // DAX 表达式
m.DisplayFolder // 显示文件夹
);
- newMeasure.FormatString = m.FormatString; // 从原始度量值复制格式字符串
+ newMeasure.FormatString = m.FormatString; // 从原度量值复制格式字符串
foreach(var c in Model.Cultures) {
- newMeasure.TranslatedNames[c] = m.TranslatedNames[c] + " YTD"; // 为每个区域设置复制翻译名称
- newMeasure.TranslatedDisplayFolders[c] = m.TranslatedDisplayFolders[c]; // 复制翻译后的显示文件夹
+ newMeasure.TranslatedNames[c] = m.TranslatedNames[c] + " YTD"; // 为每种区域设置复制已翻译的名称
+ newMeasure.TranslatedDisplayFolders[c] = m.TranslatedDisplayFolders[c]; // 复制已翻译的显示文件夹
}
}
```
@@ -154,9 +154,9 @@ foreach(var m in Selected.Measures) {
## 设置默认翻译
-有时,为所有(可见的)对象应用默认翻译会很方便。 在这种情况下,默认翻译就是对象的原始名称/说明/显示文件夹。 这样做的一个好处是:以 JSON 格式导出翻译时会包含所有翻译对象,即可用于 [SSAS Tabular Translator](https://www.sqlbi.com/tools/ssas-tabular-translator/)。
+有时,为所有(可见)对象应用默认翻译会很有用。 在这种情况下,默认翻译其实就是对象的原始名称/描述/显示文件夹。 这样做的一个好处是:以 JSON 格式导出翻译时会包含所有翻译对象,例如可用于 [SSAS Tabular Translator](https://www.sqlbi.com/tools/ssas-tabular-translator/)。
-下面的脚本会遍历模型中的所有区域设置;对每个可见对象,如果还没有翻译,就会为其分配默认值:
+以下脚本会遍历模型中的所有区域设置;对于每个可见对象,若尚无翻译,则会为其赋予默认值:
```csharp
// 将默认翻译应用到模型中所有区域设置下的所有(可见)可翻译对象:
@@ -179,13 +179,13 @@ foreach(var culture in Model.Cultures)
void ApplyDefaultTranslation(ITranslatableObject obj, Culture culture)
{
- // 仅在尚不存在翻译时才应用默认翻译:
+ // 仅当还没有翻译时,才应用默认翻译:
if(string.IsNullOrEmpty(obj.TranslatedNames[culture]))
{
// 默认名称翻译:
obj.TranslatedNames[culture] = obj.Name;
- // 默认说明翻译:
+ // 默认描述翻译:
var dObj = obj as IDescriptionObject;
if(dObj != null && string.IsNullOrEmpty(obj.TranslatedDescriptions[culture])
&& !string.IsNullOrEmpty(dObj.Description))
@@ -208,7 +208,7 @@ void ApplyDefaultTranslation(ITranslatableObject obj, Culture culture)
## 处理透视
-度量值、列、层级结构和表都提供 `InPerspective` 属性。该属性会为模型中的每个透视保存一个 True/False 值,用于指示给定对象是否属于该透视。 例如:
+度量值、列、层级结构和表都提供 `InPerspective` 属性。该属性会为模型中的每个透视保存一个 True/False 值,用来指示给定对象是否属于该透视。 比如:
```csharp
foreach(var measure in Selected.Measures)
@@ -218,23 +218,23 @@ foreach(var measure in Selected.Measures)
}
```
-上面的脚本确保所有选中的度量值在 "Inventory" 透视中可见,并在 "Reseller Operation" 透视中隐藏。
+上述脚本可确保所有选中的度量值在 "Inventory" 透视中可见,并在 "Reseller Operation" 透视中隐藏。
-除了获取/设置单个透视中的成员关系之外,`InPerspective` 属性还支持以下方法:
+除了获取/设置单个透视中的成员关系外,`InPerspective` 属性还支持以下方法:
- `<
